Architecture Overview
DMS3 software runs on network endpoint nodes 1 and consist of thin decentralized client applications or dapps 2 and a thick network protocol stack 3 that includes dapp-consistent fault tolerant information and data persistence services 4 as shown in Fig. 1: Architecture Overview.
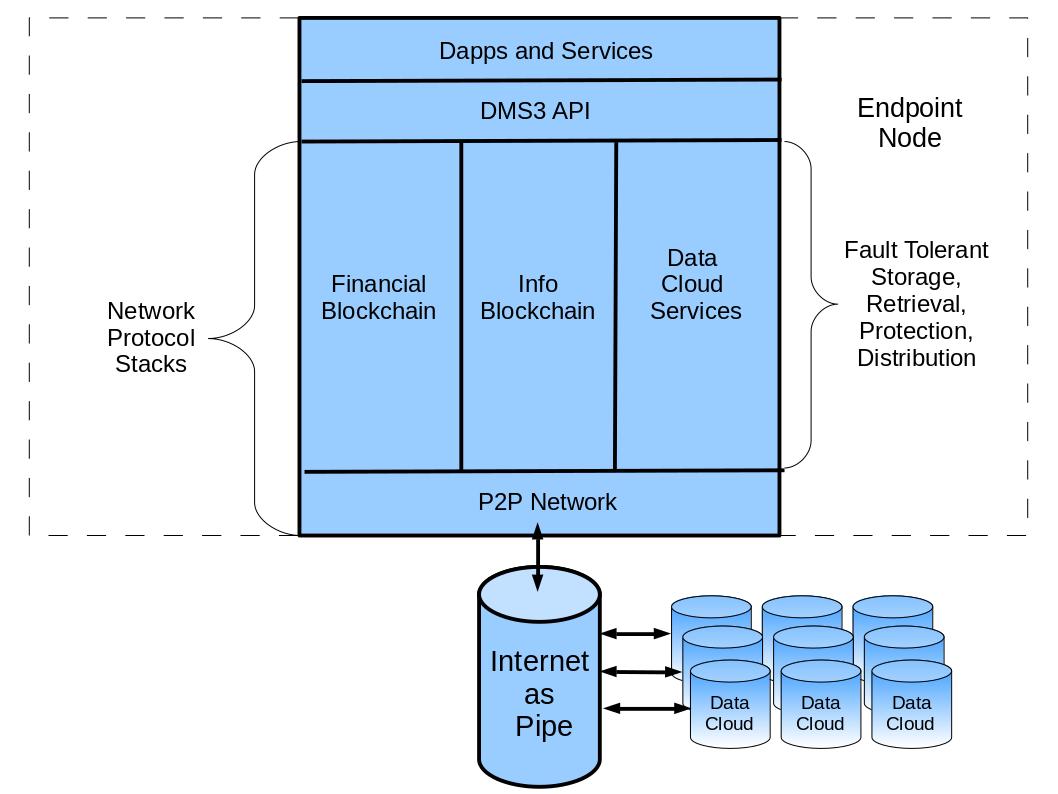 |
|---|
| Fig. 1: Architecture Overview |
DApps
DMS3 provides discovery of, and access to, decentralized applications that run on endpoint nodes. Dapp generated data persists on an endpoint node that runs a dapp.
Dapps may communicate with other compatible dapps via a locally running DMS3 API and Network Protocol Stack as the only intermediary, no web server or other third party intermediaries are involved.
DMS3 API
The DMS3 API provide a layer of isolation to dapps from the affects of changes in the network layer that implement new capabilities.
Network Protocol Stacks
The network layer consists of several major subsystems. Permission-less decentralized blockchain networks for p2p services and a centralized permission-ed network for data cloud services providing high performance access to scalable information storage, retrieval, protection, reliability, availability, and distribution services.
Financial Blockchain
A blockchain network similar to Ethereum.
Information Blockchain
A blockchain network similar to IPFS.
Data Cloud Services
Practical Byzantine Fault Tolerant services. This network provides data storage, retrieval, protection, and distribution services extending personal compute and storage node capacity via centralized network services that protect personal data and privacy without compromising endpoint control over generated data.
P2P Network
A permission-less peer-to-peer network providing disintermediated services between network nodes, based on LIBP2P used by other projects including Ethereum and IPFS.
Network Topology
The architecture makes basic assumptions about network topology to enable peer nodes to discover other nodes in the network. The following sections provide diagrams for the various network topology perspectives.
Physical Network Topology
The following residential and enterprise Physical Network Topology should be adequate for endpoint node connectivity.
P2P Logical Network Topology
The following P2P Logical Network Topology diagram provides a logical view of the permission-less p2p network.
Centralized Private Overlay Network
The following Centralized Private Overlay Network diagram provides a logical view of the permission-ed PBFT network.
Hybrid Overlay Network
The following Hybrid Overlay Network diagram provides a logical view of the hybrid permission-less and permission-ed network.
Information storage abstractions
Computing systems implement various layers of abstractions to store and manage information:
- Bit, Byte or Octet, and Block representation (ex: RAID storage)
- File representation (ex: btrfs file system)
- Database and Search Engine representations (ex: postgres SQL database, MongoDB NoSQL database, etc...)
With exponential growth in digitized information, innovations in storage systems have evolved to store an ever growing amount of information with good performance. While innovations in information retrieval (IR) systems has enabled indexing and fast retrieval of textual information.
Many modern applications use databases systems to store and manage data abstracted as structured relational data, or unstructured (document) data. Retrieval is supported using Structured Query Language (SQL), or other query languages in the case of NoSql databases. Database scaling and performance suffers when data growth is unbounded. The data stored by these applications is not transparent, each application requires embedding a search feature to provide access to data it collects.
Search engines offer a very fast retrieval technology for the discovery of web page information on the Internet, and for information stored on a desktop or within enterprise information systems. Search engines work well with textual information but don't support the robust data types needed by applications as supported by databases. Search engine performance also suffers when data growth is unbounded. Popular web search engines expose a flat view of the search information space, it is not possible to guide the search request with context or metadata input.
Furthermore, all of the above discussed information storage and retrieval systems provide data service guarantees from the storage system perspective. Every scalable application working with very large data sets is still burdened with providing its own data guarantees. A data storage abstraction layer that provides application perspective data service guarantees for all cooperating applications can provide great benefits to application developers.
DMS3 is a novel solution that combines information storage and retrieval and offers several advantages to applications developed with the DMS3 API:
- Search engine retrieval performance
- Text and application data type support
- Bounded information containers for consistent performance and scaling
- Context sensitive storage and search
- Improved data privacy and access control
- Application data consistency, reliability, safety, and recovery
- Consistent API for Internet, desktop, and enterprise search applications
- Easy information sharing between independent applications
-
endpoint nodes are compute and storage nodes of varying capacity that include SmartPhones, Tablets, Laptops, Desktops, and Servers. ↩
-
dapps are decentralized applications that run locally and store all information locally, i.e. there is no web site involved that may track personal activity. A dapp and the data it generates are strictly under the control of the individual controlling the endpoint. ↩
-
network protocol stack enables an endpoint to interact with peer endpoints and access technological capability without compromising personal security and privacy. The peer-to-peer (p2p) network protocol network implements an overlay network over the Internet reducing network threat footprint. ↩
-
fault tolerant data services unburden greenfield application developers from the complexities of implementing data scaling, reliability, and availability. ↩